
A Motivation for Concurrent-structural Modeling: The Mapping Problem
Simulators are time-consuming to specify because they model the behavior of complex hardware. Fortunately, designers have a divide and conquer strategy to manage this complexity. The design is decomposed into concurrently executing hardware blocks whose communication occurs solely between predefined communication channels (which usually end up as point-to-point wires or simple buses.)
When modeling hardware, there is a choice. Hardware can be modeled using this same decomposition strategy, which would indicate a concurrent-structural methodology or hardware can be modeled using other tools that don't quite match the decomposition strategy. This page explains why taking the latter strategy leads to models that are slow to build, often riddled with bugs, and see very little component-based reuse.
Sequential Programs as Hardware Models
One of the most common methods of constructing a hardware model, especially for high-level microprocessor models, is writing a C or C++ program that computes the total number of clock cycles it takes for a particular input set or sequence of operations. These models are often augmented to collect additional data such as power consumption, branch misprediction rate in a microprocessor, etc.
A sequential model of computation, unfortunately, leads to models that are difficult to understand, error prone to construct and modify, and code that is difficult or impossible to reuse in a modular fashion. The reasons for this are discussed in great detail in this paper.. A brief explanation for the lack of reuse is presented below.
The main drawback of a sequential model of computation is that code related to a single hardware component must be distributed throughout the software. Furthermore, modifications to a particular piece of hardware may have global implications in the code, breaking the modularity of components.
Consider the following pseudo-code sequence implementing a simulator
for a 5-stage pipeline processor presented in
the paper referenced above. The code is shown in subfigures a, b,
and c.

In (a) above, we see a typical main simulation loop for a processor implemented using a sequential language. The hardware is modeled using a function per pipeline stage in the processor. The functions communicate via global variables which, in effect, model the pipeline registers of the machine. Since later stages in the pipeline need to consume data produced by earlier stages in earlier cycles, the loop executes pipeline stages in the opposite order that an instruction flows through the pipeline. In this way later pipeline stages read the global variable when the data from an earlier cycle is stored, and then earlier pipeline stages overwrite this data.
(b) and (c) in the figure show the computation performed in the fetch and issue stages of the pipeline, respectively. In the presented pseudo-code, we see that when an instruction is issued it is also removed from the instruction queue (lines 8 and 13 in (c)). In this way the fetch logic sees any space freed in the instruction queue this cycle thus modeling a pipelined instruction queue where space freed in the current cycle is available for use in the same cycle.
Now assume that an architect would like to change the behavior of this hardware so that the instruction window slot freed in issue is not available to the fetch logic until the next cycle. At the high-level, this change is a localized change to the instruction queue in the way the signal that indicates availability in the queue is computed. Notice, however, that the changes needed to implement this change is scattered throughout the code, thus ruining the modularity of the fetch stage or the main simulator loop (in the figure, the main simulator loop contains the extra code) and partitioning code that is logically in the issue stage.
This is a relatively simple example of the partitioning of components required by certain communication patterns when using s purely sequential modeling language. In case of any doubts regarding these difficulties, a more detailed discussion regarding this and other issues is in the the paper.
Pseudo-structural Modeling Tools
We can run into the mapping problem even in tools that appear to be concurrent-structural modeling frameworks. These pseudo-structural frameworks have the proper elements for concurrent-structural modeling on the surface. Hardware blocks are contained in single software components and communication is done through a static set of interconnects. Unfortunately, these systems have have models of concurrency that force modelers to forgo the benefits of the hardware divide and conquer strategy.
The Model of Concurrency or Model of Computation (MoC) for a given structural hardware modeling system is of vital importance. Too rigid a model of computation will make it difficult or impossible to reuse component, an overly flexible model of computation may make optimization overly difficult and reduce performance to unacceptable levels. These pages will discuss the consequences of too rigid a MoC. Issues related to performance are discussed here.
A very appealing and common model of concurrency, especially in processor modeling and ad-hoc tools, is the single-invocation-per-component-per-cycle MoC. In these systems, components are supposed to roughly correspond to high-level hardware blocks and they are interconnected via communication channels. However, the MoC only allows a single invocation of the component. An alternative way that this MoC is often formulated is that an output of a given component is not available to itself (and possibly other components, in the same cycle).
This restriction is a problem because a model developed for a particular context may need rewriting before it can be used in other contexts greatly increasing the overhead for creating a reusable component.
To see this, consider the following connection of components:
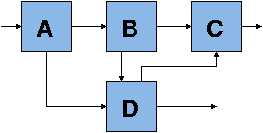
If component D is built in this configuration, a single component works just fine, since executing each component once in a topological order can be sufficient.
If we then wish to reuse component D in the specification pictured
below, notice that the communication pattern between B' and D now
require D to be partition if it can only be executed once (i.e. there
is a cycle in the graph of components and no topological sort is
possible). This type of component loop is perfectly fine provided
that there is no real combinational circular dependence. Notice then,
that the MoC's artificial execute once restriction prevents modular
reuse of component D since it needs to be partitioned.
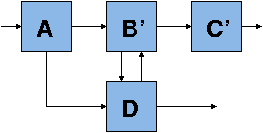
From this discussion we can see the importance of a proper model of computation so that we gain modular reusability. A survey concerning models of computation and processor simulation tools can be found in this paper. A MoC comparison among a few structural modeling tools can be found here.